XML 데이터 파싱 | Android 개발자 | Android Developers
확장성 마크업 언어(XML)는 컴퓨터에서 읽을 수 있는 형식으로 문서를 인코딩하기 위한 규칙 집합입니다. XML은 인터넷에서 데이터를 공유하는 데 흔히 사용되는 형식입니다. 뉴스 사이트나 블로
developer.android.com
이 예제를 Java로 실행했지만,
실행하는 도중에 AsyncTask가 호환이 안 된다는 것을 알았습니다.

허허.. 저는 XML parser 방식을 이해하기 위해 실행했지만,
실제 개발에 적용하실 때는 대체 방식을 찾아보시거나 Kotlin으로 개발하셔야 할 것 같네요

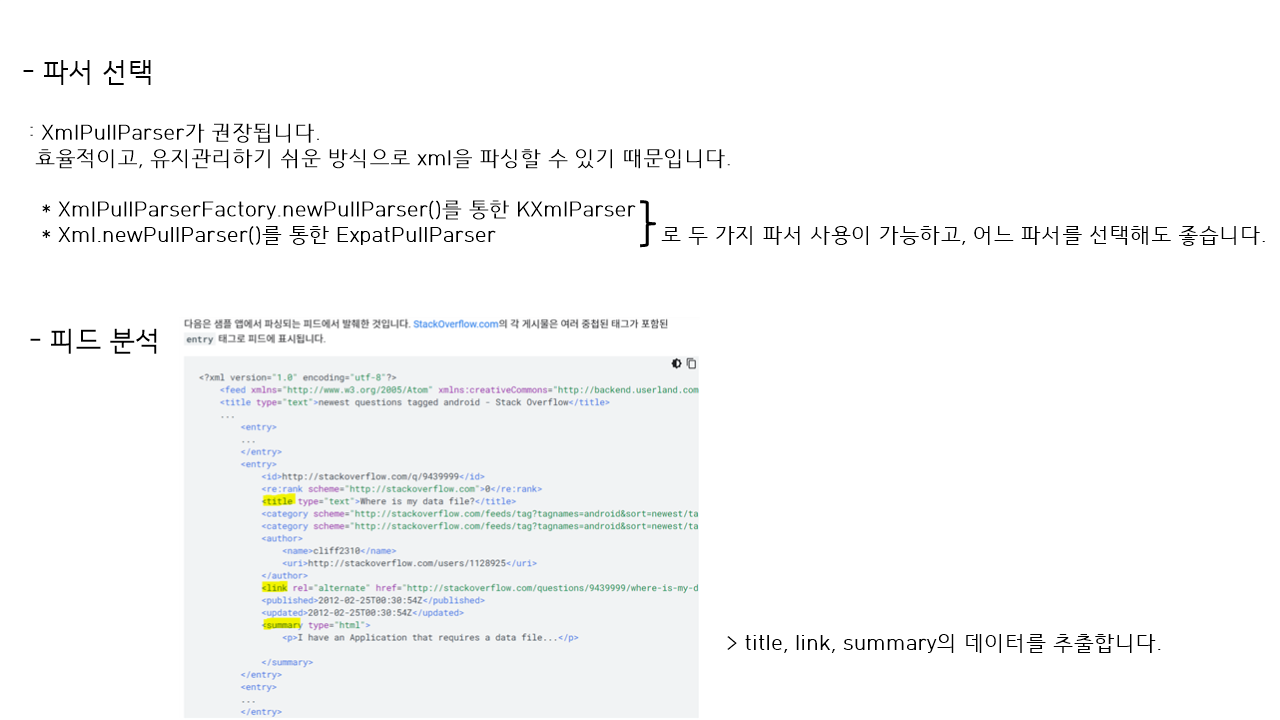


public static class Entry {
public final String title;
public final String link;
public final String summary;
private Entry(String title, String summary, String link) {
this.title = title;
this.summary = summary;
this.link = link;
}
}
// Parses the contents of an entry. If it encounters a title, summary, or link tag, hands them off
// to their respective "read" methods for processing. Otherwise, skips the tag.
private Entry readEntry(XmlPullParser parser) throws XmlPullParserException, IOException {
parser.require(XmlPullParser.START_TAG, ns, "entry");
String title = null;
String summary = null;
String link = null;
while (parser.next() != XmlPullParser.END_TAG) {
if (parser.getEventType() != XmlPullParser.START_TAG) {
continue;
}
String name = parser.getName();
if (name.equals("title")) {
title = readTitle(parser);
} else if (name.equals("summary")) {
summary = readSummary(parser);
} else if (name.equals("link")) {
link = readLink(parser);
} else {
skip(parser);
}
}
return new Entry(title, summary, link);
}
// Processes title tags in the feed.
private String readTitle(XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "title");
String title = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "title");
return title;
}
// Processes link tags in the feed.
private String readLink(XmlPullParser parser) throws IOException, XmlPullParserException {
String link = "";
parser.require(XmlPullParser.START_TAG, ns, "link");
String tag = parser.getName();
String relType = parser.getAttributeValue(null, "rel");
if (tag.equals("link")) {
if (relType.equals("alternate")){
link = parser.getAttributeValue(null, "href");
parser.nextTag();
}
}
parser.require(XmlPullParser.END_TAG, ns, "link");
return link;
}
// Processes summary tags in the feed.
private String readSummary(XmlPullParser parser) throws IOException, XmlPullParserException {
parser.require(XmlPullParser.START_TAG, ns, "summary");
String summary = readText(parser);
parser.require(XmlPullParser.END_TAG, ns, "summary");
return summary;
}
// For the tags title and summary, extracts their text values. (태그 데이터 추출)
private String readText(XmlPullParser parser) throws IOException, XmlPullParserException {
String result = "";
if (parser.next() == XmlPullParser.TEXT) {
result = parser.getText();
parser.nextTag();
}
return result;
}
...
}
* Skip() 메서드
작동 방식은 다음과 같습니다.
- 현재 이벤트가 START_TAG가 아니면 예외가 발생합니다.
- START_TAG 및 일치하는 END_TAG를 포함한 현재까지의 모든 이벤트를 사용합니다.
- 원래 START_TAG 이후 만나는 첫 번째 태그가 아니라 올바른 END_TAG에서 중지할 수 있도록 중첩 깊이를 계속 추적합니다.
따라서 현재 요소에 중첩된 요소가 있으면 depth 값은 파서가 원래 START_TAG 및 일치하는 END_TAG 사이의 모든 이벤트를 사용할 때까지 0이 되지 않습니다.
private void skip(XmlPullParser parser) throws XmlPullParserException, IOException {
if (parser.getEventType() != XmlPullParser.START_TAG) {
throw new IllegalStateException();
}
int depth = 1;
while (depth != 0) {
switch (parser.next()) {
case XmlPullParser.END_TAG:
depth--;
break;
case XmlPullParser.START_TAG:
depth++;
break;
}
}
}
XML 데이터 사용하기
다음 예제에서는 AsyncTask에서 XML 피드를 가져와 파싱합니다.
이 작업은 기본 UI 스레드 밖에서 처리됩니다. 처리가 완료되면 앱이 기본 활동(NetworkActiviry)에서 UI를 업데이트합니다.
LoadPage( ) 메서드의 동작 방식은 다음과 같습니다.
- XML 피드의 URL을 포함한 문자열 변수를 초기화합니다.
- 사용자 설정과 네트워크 연결을 허용하면, newDownloadXmlTask( ).execute(url)을 호출합니다. 그러면 새로운 DownloadXmlTask 객체(AsyncTask 서브클래스)를 인스턴스화하고, execute( ) 메서드를 실행합니다.
- 이 메서드는 피드를 다운로드하고, 파싱하여 UI에 표시할 문자열 결과를 반환합니다.
public class NetworkActivity extends Activity {
public static final String WIFI = "Wi-Fi";
public static final String ANY = "Any";
private static final String URL = "http://stackoverflow.com/feeds/tag?tagnames=android&sort=newest";
// Whether there is a Wi-Fi connection.
private static boolean wifiConnected = false;
// Whether there is a mobile connection.
private static boolean mobileConnected = false;
// Whether the display should be refreshed.
public static boolean refreshDisplay = true;
public static String sPref = null;
...
// Uses AsyncTask to download the XML feed from stackoverflow.com.
public void loadPage() {
if((sPref.equals(ANY)) && (wifiConnected || mobileConnected)) {
new DownloadXmlTask().execute(URL);
}
else if ((sPref.equals(WIFI)) && (wifiConnected)) {
new DownloadXmlTask().execute(URL);
} else {
// show error
}
}
AsyncTask 서브클래스인 DownloadXmlTask는 다음 메서드를 구현합니다.
- doInBackground( )가 loadXmlFromNetwork( ) 메서드를 실행합니다. 피드 URL을 매개변수로 전달합니다. loadXmlFromNetwork( ) 메서드가 피드를 가져와 처리하고, 작업이 완료되면 결과 문자열을 다시 전달합니다.
// Implementation of AsyncTask used to download XML feed from stackoverflow.com.
private class DownloadXmlTask extends AsyncTask<String, Void, String> {
@Override
protected String doInBackground(String... urls) {
try {
return loadXmlFromNetwork(urls[0]);
} catch (IOException e) {
return getResources().getString(R.string.connection_error);
} catch (XmlPullParserException e) {
return getResources().getString(R.string.xml_error);
}
}
@Override
protected void onPostExecute(String result) {
setContentView(R.layout.main);
// Displays the HTML string in the UI via a WebView
WebView myWebView = (WebView) findViewById(R.id.webview);
myWebView.loadData(result, "text/html", null);
}
}
다음은 DownloadXmlTask에서 호출된 loadXmlFromNetwork( ) 메서드입니다.
1. StackOverflowXmlParser를 인스턴스화하고, Entry 객체에 대한 List를 만들어 XML feed에서 추출한 값을 보관합니다.
2. downloadUrl( )을 호출해 피드를 가져오고, InputStream으로 반환합니다.
3. StackOverflowXmlParser를 사용해 InputStream으로 반환합니다.
3. StackOverflowXmlParser를 사용해 InputStream을 파싱합니다. feed에서 가져온 데이터로 entries List를 저장합니다.
4. entries를 처리하고, feed 데이터와 HTML 마크업을 결합합니다.
5. onPostExeecute( )를 사용해 기본 활동 UI에 표시되는 HTML 문자열을 반환합니다.
// Uploads XML from stackoverflow.com, parses it, and combines it with
// HTML markup. Returns HTML string.
private String loadXmlFromNetwork(String urlString) throws XmlPullParserException, IOException {
InputStream stream = null;
// Instantiate the parser
StackOverflowXmlParser stackOverflowXmlParser = new StackOverflowXmlParser();
List<Entry> entries = null;
String title = null;
String url = null;
String summary = null;
Calendar rightNow = Calendar.getInstance();
DateFormat formatter = new SimpleDateFormat("MMM dd h:mmaa");
// Checks whether the user set the preference to include summary text
SharedPreferences sharedPrefs = PreferenceManager.getDefaultSharedPreferences(this);
boolean pref = sharedPrefs.getBoolean("summaryPref", false);
StringBuilder htmlString = new StringBuilder();
htmlString.append("<h3>" + getResources().getString(R.string.page_title) + "</h3>");
htmlString.append("<em>" + getResources().getString(R.string.updated) + " " +
formatter.format(rightNow.getTime()) + "</em>");
try {
stream = downloadUrl(urlString);
entries = stackOverflowXmlParser.parse(stream);
// Makes sure that the InputStream is closed after the app is
// finished using it.
} finally {
if (stream != null) {
stream.close();
}
}
// StackOverflowXmlParser returns a List (called "entries") of Entry objects.
// Each Entry object represents a single post in the XML feed.
// This section processes the entries list to combine each entry with HTML markup.
// Each entry is displayed in the UI as a link that optionally includes
// a text summary.
for (Entry entry : entries) {
htmlString.append("<p><a href='");
htmlString.append(entry.link);
htmlString.append("'>" + entry.title + "</a></p>");
// If the user set the preference to include summary text,
// adds it to the display.
if (pref) {
htmlString.append(entry.summary);
}
}
return htmlString.toString();
}
// Given a string representation of a URL, sets up a connection and gets
// an input stream.
private InputStream downloadUrl(String urlString) throws IOException {
URL url = new URL(urlString);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setReadTimeout(10000 /* milliseconds */);
conn.setConnectTimeout(15000 /* milliseconds */);
conn.setRequestMethod("GET");
conn.setDoInput(true);
// Starts the query
conn.connect();
return conn.getInputStream();
}
* 예시

간단하게 버튼 클릭하면 parse된 데이터가 화면에 보이도록 구현했다. (feat. kotlin)
'OLD_달려라 > Android' 카테고리의 다른 글
| 개인 프로젝트 ] (Solved)Parse XML data problem (0) | 2021.01.07 |
|---|---|
| BUS APP 개발 참고 문서 (0) | 2021.01.07 |
| Inactivity, disconnecting from the service (0) | 2020.11.06 |
| Firebase + Android ] 앱이 Google 서버와 통신했는지 확인하는 중입니다. 앱을 제거한 후 다시 설치해야 할 수도 있습니다. (0) | 2020.11.06 |
| Inactivity, disconnecting from the service (0) | 2020.10.18 |


댓글